




I. Introduction▲
La première chose que je voudrais mentionner est qu'il existe déjà un nombre convenable d'articles décrivant les tampons GPU-CPU persistants. J'ai spécialement beaucoup appris de Persistent mapped buffers @ferransole.wordpress.com et Maximizing VBO upload performance! - javagaming .
Cet article sert de résumé et de récapitulatif à l'utilisation de techniques modernes pour gérer les mises à jour des tampons. J'ai utilisé ces techniques dans mon système de particules - attendez un peu, un futur article sur les optimisations des outils de rendu va arriver.
OK, mais parlons de notre héros principal : la technique des tampons GPU-CPU persistants.
Elle est apparue avec l'extension ARB_buffer_storage et elle est au cœur d' OpenGL 4.4. Elle vous permet de définir le tampon une fois et de conserver son pointeur pour toujours. Aucun besoin de le dissocier (glUnmapBuffer) et de libérer le pointeur du pilote… Toute la magie s'opère en sous-main.
L'association persistante de la mémoire GPU au CPU est également incluse dans un jeu de techniques de l'OpenGL moderne appelé « AZDO » - système approchant le pilote zéro . Comme vous pouvez l'imaginer, en associant le tampon une seule fois, nous réduisons significativement le nombre d'appels aux lourdes fonctions d'OpenGL et, le plus important, nous combattons les problèmes de synchronisation.
Cette approche peut simplifier le code de rendu et le rend plus robuste, stable en essayant de rester le plus possible du côté GPU. Chaque transfert de données entre le CPU et le GPU sera toujours beaucoup plus lent qu'une communication GPU interne.
II. Déplacer les données▲
Intéressons-nous maintenant au processus de rafraîchissement des données dans le tampon. Nous pouvons l'effectuer au moins de deux façons différentes : glBuffer*Data et glMapBuffer*.
Pour être précis : nous voulons déplacer des données depuis la mémoire de l'application (CPU) vers le GPU de façon que les données puissent être utilisées pour le rendu. Je me suis spécialement intéressé au cas où nous l'effectuons à chaque image, comme avec un système de particules : nous calculons les nouvelles positions dans le CPU, mais ensuite nous voulons les dessiner. Un transfert mémoire CPU vers GPU est nécessaire. Un exemple encore plus compliqué serait de rafraîchir des images vidéo. Vous chargez des données depuis un fichier média, décodez le fichier puis modifiez la texture des données avant de l'afficher.
Un tel processus est souvent appelé flux .
En d'autres termes, le CPU écrit les données, le GPU les lit.
Bien que je mentionne « un déplacement », le GPU peut effectivement lire directement les données dans la mémoire système (en utilisant GART ). Ainsi, il n'y a pas besoin de copier les données d'un tampon mémoire du côté CPU, vers un tampon mémoire du côté GPU. Dans cette approche, on devrait plutôt penser à « rendre les données visibles » au GPU.
II-A. glBufferData/glBufferSubData▲
Ces deux procédures (disponibles depuis OpenGL 1.5 ! ) copient vos données entrées dans la mémoire GPU . Lorsque c'est fait, un transfert DMA asynchrone peut démarrer et la procédure invoquée se termine. Après cet appel, vous pouvez détruire votre morceau de données d'entrée.
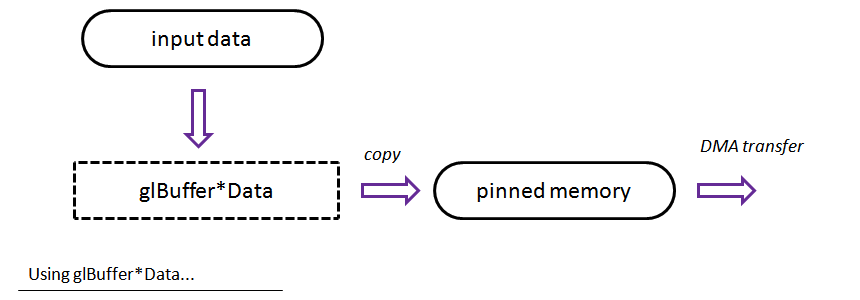
Le dessin ci-dessus montre le flux théorique pour cette méthode : les données sont passées aux fonctions glBuffer*Data et ensuite OpenGL effectue le transfert DMA vers le GPU…
glBufferData invalide et réalloue le tampon entier. Utilisez glBufferSubData pour seulement mettre à jour les données à l'intérieur.
II-B. glMap*/glUnmap*▲
Avec l'approche associative, vous obtenez simplement un pointeur vers la mémoire GPU (cela peut dépendre de votre implémentation réelle ! ). Vous pouvez copier vos données à envoyer au GPU puis appeler glUnmap pour signifier au pilote que vous avez terminé la mise à jour. Ainsi, cela ressemble à l'approche avec glBufferSubData, mais vous gérez la copie des données vous-même. De plus, vous avez un meilleur contrôle sur l'intégralité du processus.
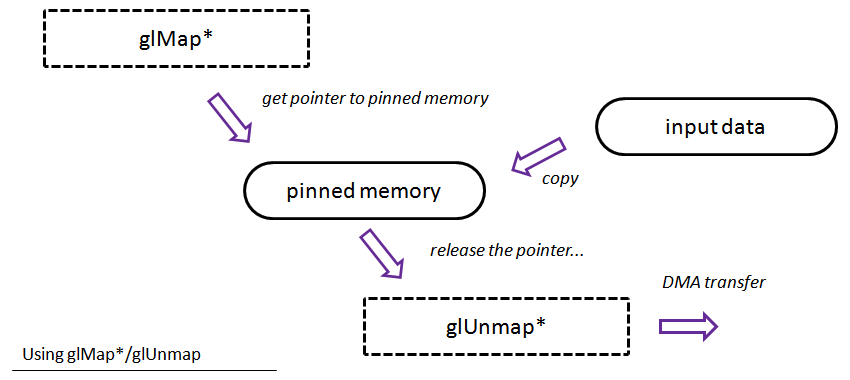
Le flux théorique pour cette méthode : vous obtenez un pointeur vers (probablement) la mémoire GPU, ensuite vous pouvez copier vos données originales (ou bien vous les calculez) et à la fin vous devez libérer le pointeur grâce à la méthode glUnmapBuffer.
Toutes les méthodes citées ci-dessus semblent assez faciles : vous payez seulement pour le transfert mémoire. Cela pourrait se passer comme ça si seulement il n'y avait pas des choses comme la synchronisation…
III. Synchronisation▲
Malheureusement, la vie n'est pas si simple : vous devez vous souvenir que le GPU et le CPU (et même le pilote) fonctionnent de façon asynchrone. Lorsque vous effectuez un appel de dessin, celui-ci ne sera pas exécuté immédiatement… Il va être enregistré dans la file de commandes, mais sera exécuté probablement plus tard par le GPU. Lorsque nous mettons à jour le tampon de données, nous pouvons facilement avoir une pause - le GPU attendra pendant la mise à jour de données. Nous devons gérer cela intelligemment.
Par exemple, lorsque vous appelez glMapBuffer, le pilote peut créer un mutex de telle sorte que le tampon (qui est une ressource partagée) ne soit pas modifié par le CPU et le GPU au même moment. Si cela se produit souvent, nous perdons une grande partie de la puissance GPU. Le GPU peut bloquer même dans une situation où votre tampon est seulement enregistré en vue du rendu et pas en cours de lecture.
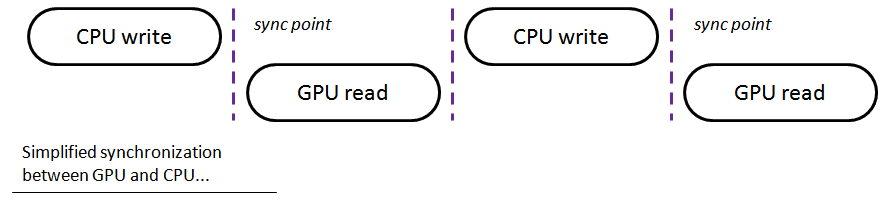
Dans la figure ci-dessus, j'ai essayé de montrer une vue très générique et simplifiée de : comment le CPU et le GPU fonctionnent quand ils doivent se synchroniser - en s'attendant mutuellement. Dans un scénario réel, ces espaces peuvent avoir des durées différentes et il peut y avoir plusieurs points de synchronisation dans une image. Moins vous avez d'attentes et plus vous avez de performance.
Et donc, réduire les problèmes de synchronisation est une autre incitation à tout effectuer dans le GPU.
IV. Double (multiple) tampon/recyclage▲
L'idée recommandée est d'utiliser un double ou même un triple tampon pour résoudre les problèmes de synchronisation :
- créer deux tampons ;
- mettre à jour le premier ;
- pour la prochaine image, mettre à jour le second ;
- échanger les pointeurs de tampons…
De cette façon, le GPU peut dessiner (lire) le premier tampon pendant que vous mettez à jour le deuxième.
Comment faire cela avec OpenGL ?
- Utilisez explicitement plusieurs tampons et utilisez un algorithme rotatif pour les mettre à jour.
-
Utilisez glBufferData avec un pointeur NULL avant chaque mise à jour :
- le tampon entier sera recréé et vous pouvez stocker vos données à une position totalement nouvelle ;
- l'ancien tampon sera utilisé par le GPU - aucune synchronisation ne sera nécessaire ;
- le GPU va probablement comprendre que les allocations de tampons suivantes seront similaires et il utilisera probablement le même bloc mémoire. Je me souviens que cette approche n'était pas suggérée dans les versions plus anciennes d'OpenGL.
-
Utilisez glMapBufferRange avec GL_MAP_INVALIDATE_BUFFER_BIT :
- en outre, utilisez le bit UNSYNCHRONIZED et effectuez la synchronisation vous-même ;
- il existe également une procédure intitulée glInvalidateBufferData qui effectue le même travail.
Triple tampon
Le GPU et le CPU fonctionnent de façon asynchrone… Mais il y a également un autre facteur : le pilote. Il peut arriver (et sur les implémentations de pilote de PC, cela arrive souvent) que le pilote fonctionne aussi de façon asynchrone. Pour résoudre cela, vous devez considérer le triple tampon, un scénario de synchronisation encore plus compliqué :
- un tampon pour le CPU ;
- un tampon pour le pilote ;
- un tampon pour le GPU ;
De cette manière, il ne devrait pas y avoir de blocage dans le traitement de données, mais vous devrez sacrifier un peu plus de mémoire pour vos données.
Vous trouverez plus de documentation sur le blog @hacksoflife
V. L'association persistante de tampon ▲
OK, nous avons couvert les techniques communes pour les flux de données, mais maintenant parlons des tampons GPU-CPU persistants plus en détail.
Hypothèses :
- GL_ARB_buffer_storage doit être disponible ou OpenGL 4.4
V-A. Création▲
glGenBuffers(1, &vboID);
glBindBuffer(GL_ARRAY_BUFFER, vboID);
flags = GL_MAP_WRITE_BIT | GL_MAP_PERSISTENT_BIT | GL_MAP_COHERENT_BIT;
glBufferStorage(GL_ARRAY_BUFFER, MY_BUFFER_SIZE, 0, flags);V-B. Association (seulement après création…)▲
flags = GL_MAP_WRITE_BIT | GL_MAP_PERSISTENT_BIT | GL_MAP_COHERENT_BIT;
myPointer = glMapBufferRange(GL_ARRAY_BUFFER, 0, MY_BUFFER_SIZE, flags);V-C. Mise à jour▲
// attendre le tampon
// prendre juste le pointeur (myPointer) et modifier les données sous-jacentes
// verrouiller le tamponComme le suggère le nom, cela vous autorise à associer le tampon une fois et de conserver le pointeur indéfiniment. En même temps, il vous reste le problème de synchronisation - c'est pour cela qu'il y a des commentaires à propos de l'attente et du verrouillage du tampon dans le code ci-dessus.
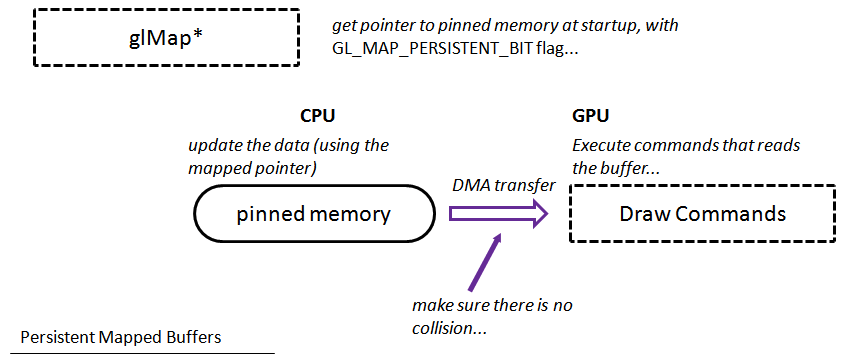
Sur le schéma, vous pouvez constater qu'en première place nous devons obtenir un pointeur sur le tampon mémoire (mais nous ne devons le faire qu'une seule fois), et ensuite nous pouvons mettre à jour les données (sans appel spécifique à OpenGL). La seule action supplémentaire que nous devons effectuer est la synchronisation ou être sûr que le GPU n'ira pas lire pendant que nous écrivons au même moment. Tous les transferts DMA nécessaires sont invoqués par le pilote.
Le drapeau GL_MAP_COHERENT_BIT rend vos modifications en mémoire atomiquement visibles par le GPU. Sans ce drapeau, vous devriez manuellement établir une barrière mémoire. Bien qu'il semble que le GL_MAP_COHERENT_BIT soit plus lent qu'une gestion manuelle et explicite de barrières mémoire et de synchronisation, mes premiers tests ne montrent aucune différence significative. Je dois passer un peu plus de temps sur ce sujet… Vous avez peut-être une opinion différente sur ce sujet ? En fait, même dans la présentation initiale AZDO, les auteurs mentionnent l'utilisation de GL_MAP_COHERENT_BIT ce ne devrait donc pas être un sérieux problème.
V-D. Synchronisation▲
// attente du tampon
GLenum waitReturn = GL_UNSIGNALED;
while (waitReturn != GL_ALREADY_SIGNALED && waitReturn != GL_CONDITION_SATISFIED)
{
waitReturn = glClientWaitSync(syncObj, GL_SYNC_FLUSH_COMMANDS_BIT, 1);
}
// verrouillage du tampon
glDeleteSync(syncObj);
syncObj = glFenceSync(GL_SYNC_GPU_COMMANDS_COMPLETE, 0);Lorsque nous écrivons dans le tampon, nous plaçons un objet de synchronisation. Puis, dans l'image suivante, nous devons attendre que cet objet de synchronisation soit signalé. En d'autres termes, nous devons attendre que le GPU termine toutes les commandes avant de positionner l'objet de synchronisation.
VI. Triple tampon▲
Mais nous pouvons faire mieux : en utilisant un triple tampon, nous pouvons être sûrs que GPU et CPU n'accèderont pas aux mêmes données dans le tampon :
- allouer un tampon avec trois fois la taille originale ;
- l'associer définitivement ;
- bufferID = 0 ;
-
mettre à jour / Dessiner
- mettre à jour seulement la zone pointée par bufferID dans le tampon,
- dessiner cette zone,
- incrémenter le bufferID : bufferID = (bufferID+1)%3.
De cette manière, dans l'image suivante, vous mettrez à jour une autre partie du tampon et comme ça il n'y aura aucun conflit.
Une autre façon de procéder serait de créer trois tampons séparés et de les mettre à jour de façon similaire.
VII. Démonstration▲
J'ai emprunté une application démo dans les exemples de Ferran Sole et je l'ai un peu étendue.
Vous trouverez les archives github ici : fenbf/GLSamples
- nombre de triangles configurable ;
- nombre de tampons configurable : simple/double/triple ;
- synchronisation optionnelle ;
- drapeau de débogage optionnel ;
- mode test de performance ;
-
sortie :
- nombre d'images,
- compteur qui s'incrémente à chaque fois qu'une attente de tampon se produit.
Comment ça marche :
- l'application montre quelques triangles 2D tournants (wow ! ) ;
- les triangles sont modifiés dans le CPU et envoyés (flux) au GPU ;
- le dessin est basé sur la commande glDrawArrays ;
- en mode comparatif, j'exécute cette application pendant N secondes (habituellement 5 s) et je compte combien d'images j'ai obtenues ;
- de plus, j'utilise un compteur qui s'incrémente chaque fois que j'attends le tampon ;
- la synchronisation verticale est désactivée.
Particularités :
- le nombre de triangles est modifiable ;
- le nombre de tampons est configurable ;
- la synchronisation est optionnelle ;
- le mode débogage est optionnel ;
- mode comparatif (quitte l'application après N secondes).
VII-A. Morceaux de code▲
VII-A-1. Tampon initial▲
size_t bufferSize{ gParamTriangleCount * 3 * sizeof(SVertex2D)};
if (gParamBufferCount > 1)
{
bufferSize *= gParamBufferCount;
gSyncRanges[0].begin = 0;
gSyncRanges[1].begin = gParamTriangleCount * 3;
gSyncRanges[2].begin = gParamTriangleCount * 3 * 2;
}
flags = GL_MAP_WRITE_BIT | GL_MAP_PERSISTENT_BIT | GL_MAP_COHERENT_BIT;
glBufferStorage(GL_ARRAY_BUFFER, bufferSize, 0, flags);
gVertexBufferData = (SVertex2D*)glMapBufferRange(GL_ARRAY_BUFFER,
0, bufferSize, flags);VII-A-2. Affichage▲
void Display() {
glClear(GL_COLOR_BUFFER_BIT);
gAngle += 0.001f;
if (gParamSyncBuffers)
{
if (gParamBufferCount > 1)
WaitBuffer(gSyncRanges[gRangeIndex].sync);
else
WaitBuffer(gSyncObject);
}
size_t startID = 0;
if (gParamBufferCount > 1)
startID = gSyncRanges[gRangeIndex].begin;
for (size_t i(0); i != gParamTriangleCount * 3; ++i)
{
gVertexBufferData[i + startID].x = genX(gReferenceTrianglePosition[i].x);
gVertexBufferData[i + startID].y = genY(gReferenceTrianglePosition[i].y);
}
glDrawArrays(GL_TRIANGLES, startID, gParamTriangleCount * 3);
if (gParamSyncBuffers)
{
if (gParamBufferCount > 1)
LockBuffer(gSyncRanges[gRangeIndex].sync);
else
LockBuffer(gSyncObject);
}
gRangeIndex = (gRangeIndex + 1) % gParamBufferCount;
glutSwapBuffers();
gFrameCount++;
if (gParamMaxAllowedTime > 0 &&
glutGet(GLUT_ELAPSED_TIME) > gParamMaxAllowedTime)
Quit();
}VII-A-3. Comptage des attentes▲
void WaitBuffer(GLsync& syncObj)
{
if (syncObj)
{
while (1)
{
GLenum waitReturn = glClientWaitSync(syncObj,
GL_SYNC_FLUSH_COMMANDS_BIT, 1);
if (waitReturn == GL_ALREADY_SIGNALED ||
waitReturn == GL_CONDITION_SATISFIED)
return;
gWaitCount++; // the counter
}
}
}VII-B. Cas de test▲
J'ai créé un simple script de commandes qui :
- lance le test pour 10, 100, 1000, 2000 et 5000 triangles ;
-
chaque test (prend cinq secondes) :
- simple tampon CPU-GPU persistant avec synchronisation,
- simple tampon CPU-GPU persistant sans synchronisation,
- double tampon CPU-GPU persistant avec synchronisation,
- double tampon CPU-GPU persistant sans synchronisation,
- triple tampon CPU-GPU persistant avec synchronisation,
- simple tampon CPU-GPU persistant sans synchronisation,
- simple tampon orphelin CPU-GPU standard glBuffer*Data,
- simple tampon non-orphelin CPU-GPU standard glBuffer*Data,
- simple tampon orphelin CPU-GPU standard glMapBuffer,
- simple tampon non orphelin CPU-GPU standard glMapBuffer ;
- au total 5 * 10 * 5 s = 250 s ;
- no_sync signifie qu'il n'y a pas de verrouillage ou d'attente pour la plage de mémoire du tampon. Cela peut potentiellement générer une situation de compétition et même un plantage de l'application - à utiliser à vos propres risques ! (Dans mon cas, rien n'est arrivé - peut-être quelques sommets fluctuants :) ) ;
- 2000 triangles utilisent : 2000 * 3 * 2 * 4 octets = 48 Ko par image. C'est vraiment un petit nombre. Dans le déroulement de cette expérience, je vais essayer de l'augmenter et charger un peu plus la bande passante CPU-GPU.
Recyclage du tampon :
- pour glMapBufferRange j'ajoute le drapeau GL_MAP_INVALIDATE_BUFFER_BIT ;
- pour glBuffer*Data j'appelle glBufferData(NULL) puis appel normal de glBufferSubData.
VII-C. Résultats▲
Tous les résultats peuvent être consultés sur github : GLSamples/projet/résultats.
VII-C-1. 100 triangles▲
GeForce GTX 460 (Fermi), Sandy Bridge Core i5 2400, 3,1 GHZ
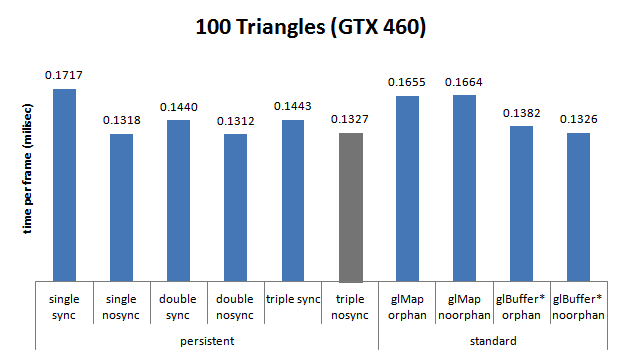
- simple tampon: 37 887 ;
- double tampon: 79 658 ;
- triple buffering: 0.
AMD HD5500, Sandy Bridge Core i5 2400, 3.1 GHZ
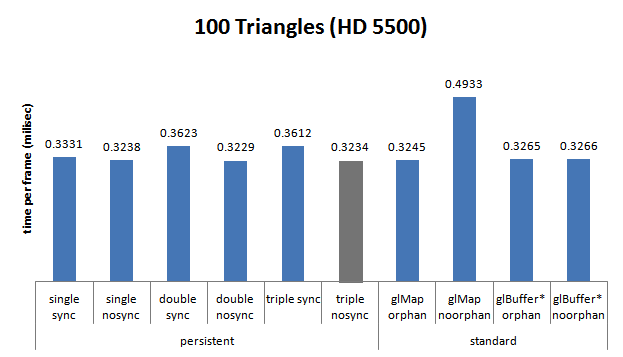
- simple tampon: 1 594 647 ;
- double tampon: 35 670 ;
- triple tampon: 0.
Nvidia GTX 770 (Kepler), Sandy Bridge i5 2500k @4ghz
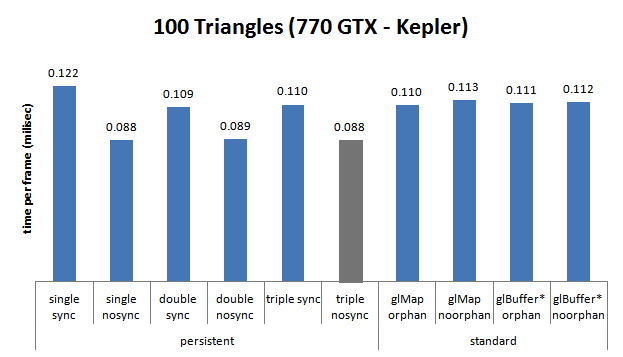
- simple tampon : 21 863 ;
- double tampon : 28 241 ;
- triple tampon: 0.
Nvidia GTX 850M (Maxwell), Ivy Bridge i7-4710HQ
- simple tampon : 0 ;
- double tampon : 0 ;
- triple tampon : 0.
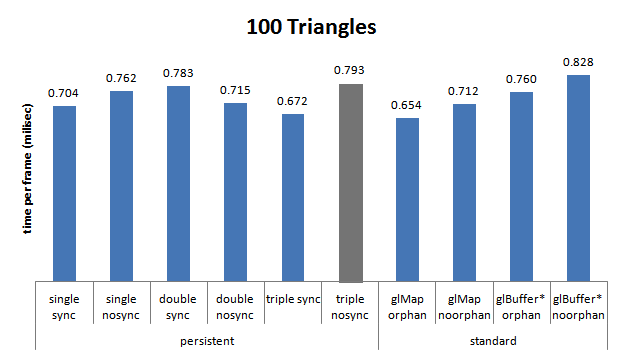
Tous GPU
Avec Intel HD4400 et NV 720M
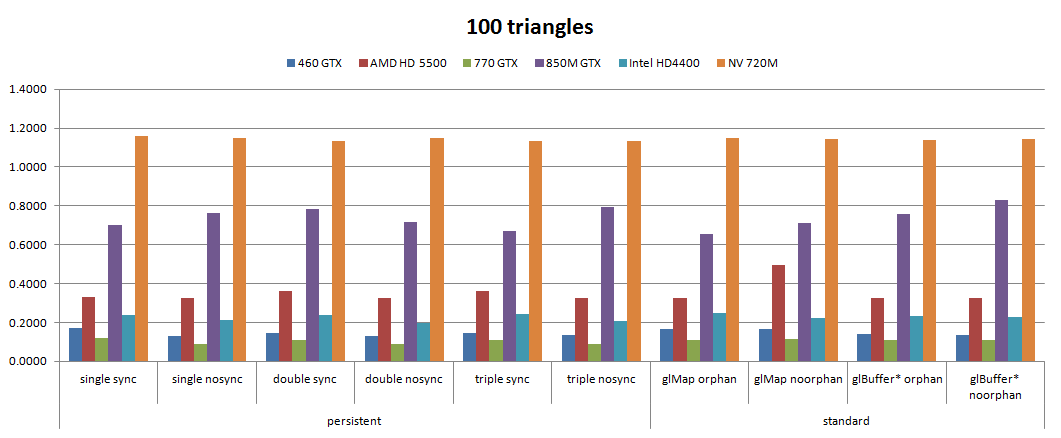
VII-C-2. 2000 triangles▲
GeForce 460 GTX (Fermi), Sandy Bridge Core i5 2400, 3.1 GHZ
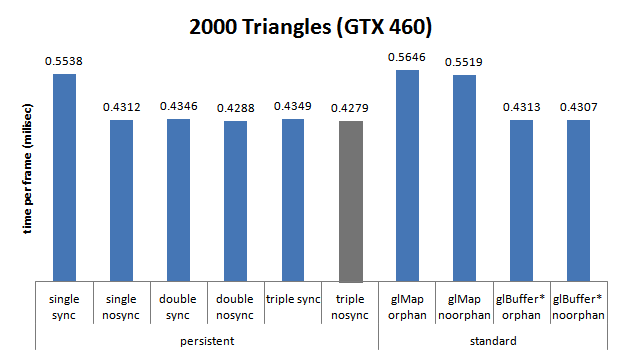
- simple tampon : 2411 ;
- double tampon : 4 ;
-
triple tampon : 0.
AMD HD5500, Sandy Bridge Core i5 2400, 3.1 GHZ
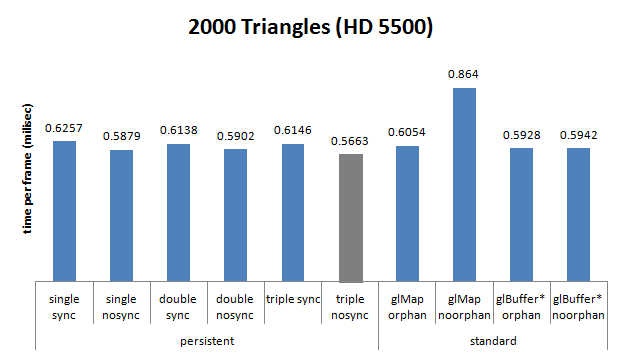
-
simple tampon : 79 462 ;
-
double tampon : 0 ;
-
triple tampon : 0.
Nvidia GTX 770 (Kepler), Sandy Bridge i5 2500k @4ghz
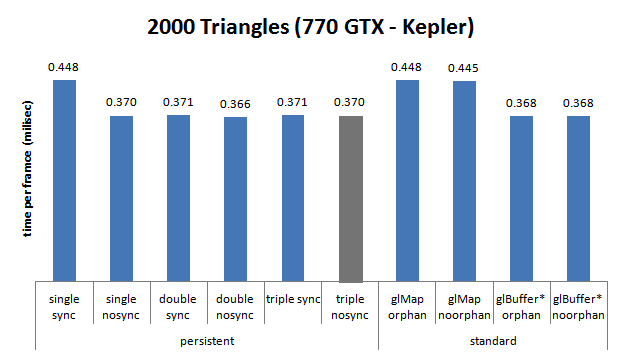
-
simple tampon : 10 405 ;
-
double tampon : 404 ;
-
triple tampon : 0.
Nvidia GTX 850M (Maxwell), Ivy Bridge i7-4710HQ
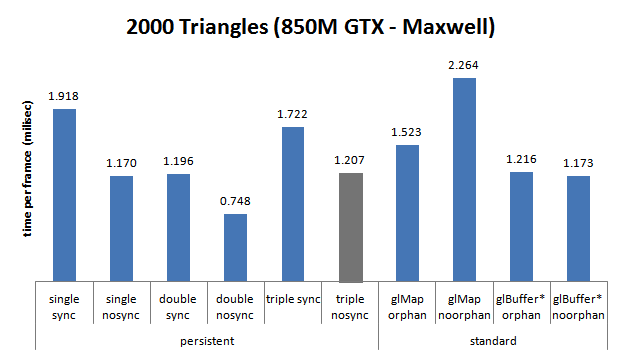
-
simple tampon : 8256 ;
-
double tampon : 91 ;
- triple tampon : 0.
Tous GPU
avec Intel HD4400 et NV 720M
VII-D. Résumé▲
-
Les tampons persistants CPU-GPU avec triple tampon sans synchronisation semblent être l'approche la plus rapide dans la plupart des scenarii testés.
- Seule la carte graphique Maxwell (850M) pose problème : elle est lente pour 100 triangles et il vaut mieux utiliser un double tampon pour 2000 triangles.
-
Les tampons CPU-GPU persistants avec double tampon semblent être légèrement plus lents qu'avec un triple tampon, avec parfois un compteur d'attentes qui n'est pas à 0. Ce qui signifie que nous devons attendre le tampon. Le triple tampon ne présente pas ce genre de problème et donc il n'y a pas besoin de synchronisation.
- Utiliser un double tampon sans synchronisation peut fonctionner, mais nous devons nous attendre à la présence de quelques artefacts (je dois creuser ce point).
- Un simple tampon CPU-GPU persistant avec synchronisation est assez lent sur les GPU Nvidia.
- L'utilisation de glMapBuffer sans synchronisation est l'approche la plus lente.
- Il est intéressant de noter que le glBuffer*Data avec le recyclage semble être comparable aux tampons CPU-GPU persistants. De telle sorte qu'un vieux code utilisant cette approche pourrait quand même être assez rapide.
VII-E. Apportez votre aide !▲
Si vous souhaitez m'aider, vous pouvez lancer les comparatifs vous-même et m'envoyer les résultats à (bartlomiej POINT filipek CHEZ gmail).
Windows seulement, désolé :)
Allez dans le fichier benchmark_pack et exécutez le fichier batch run_from_10_to_5000.bat.
run_from_10_to_5000.bat > my_gpu_name.txt
Le fichier lance tous les tests et dure environ 250 secondes.
Si vous n'êtes pas sûr que votre GPU supporte l'extension ARB_buffer_storage, vous pouvez lancer simplement persistent_mapped_buffers.exe et vous connaitrez les problèmes potentiels.
VIII. Conclusion▲
C'est un long article, mais j'espère avoir tout expliqué de façon décente. Nous avons parcouru une approche standard de mise à jour de tampons (flux de données), et vu notre problème principal : la synchronisation. Puis, nous avons décrit l'utilisation des tampons mappés persistants.
Devons-nous utiliser les tampons mappés persistants ? Voici, un bref résumé à ce propos :
Pour
- faciles à utiliser ;
- le pointeur obtenu peut être utilisé à travers toute l'application ;
-
dans la plupart des cas, la performance est améliorée lors des mises à jour fréquentes des données (lorsque les données proviennent du côté CPU)
- réduction des surcouts du pilote,
- diminution des attentes du GPU ;
- conseillé dans les techniques AZDO.
Contre
- ne pas utiliser avec des tampons statiques ou des tampons qui ne nécessitent pas de rafraîchissement CPU ;
- meilleure performance avec des triples tampons (peut créer un problème avec des grands tampons, car vous devez allouer beaucoup de mémoire) ;
- nécessité d'effectuer une synchronisation explicite ;
- en OpenGL 4.4, car seuls les derniers modèles de GPU le supportent.
Dans un futur article, je partagerai mes résultats obtenus avec l'application démo. J'ai comparé l'approche glMapBuffer avec celle de glBuffer*Data et l'association persistante.
IX. Questions intéressantes▲
- Cette extension est-elle meilleure ou pire que l'AMD_pinned_memory ?
- Que se passe-t-il si vous oubliez de synchroniser ou que vous le faites d'une mauvaise manière ? Je n'ai jamais obtenu de plantage ou difficilement vu d'artefacts, mais quel est le résultat attendu dans telle situation ?
-
Que se passe-t-il si vous oubliez d'utiliser
GL_MAP_COHERENT_BIT
?
La différence est-elle significative ?
X. Références▲
- [PDF] OpenGL Insights, Chapter 28 - Asynchronous Buffer Transfers by Ladislav Hrabcak and Arnaud Masserann, a free Chapter from [OpenGL Insights].(http://openglinsights.com/)
- Persistent mapped buffers @ferransole.wordpress.com
- Maximizing VBO upload performance! @Java-Gaming.org Forum
- Buffer Object @OpenGL Wiki
- Buffer Object Streaming @OpenGL Wiki
- persistent buffer mapping - what kind of magic is this? @OpenGL Forum
XI. Remerciements▲
Cet article est une traduction autorisée de l'article de Bartlomiej Filipek. Bartlomiej Filipek est un développeur polonais. Il écrit, sur son blog, des articles sur le C++ et la programmation graphique.
Merci aussi à ClaudeLELOUP pour sa relecture orthographique.